1.二叉树创建的3种方法
在嵌套法创建二叉树的过程中,递归终止条件是十分重要设置的一环。节点数据是char类型的二叉树,嵌套创建时,很多人会用一个字符,比如输入流中的“ ”(空格)来设置递归结束。倘若节点数据为int类型,则稍微复杂,首先我们在输入时必须使用“空格,制表,换行”这3者之一间隔输入的数,且cin读取数据时候cin会跳过三种空格,因此有的人使用某个数比如“0, -1”设置递归终止,但是要求某个节点的数值就是递归终止判断条件所设置的值比如‘-1’呢,显然这不符合程序的完整性。基于此,本文提供了一种思路。
这里,我们总结了3种二叉树创建方法。约定,二叉树节点定义如下:
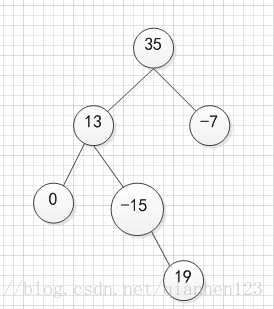
typedef struct BinaryTreeNode { int data; BinaryTreeNode * leftchild; BinaryTreeNode * rightchild; }Node,*NodePoint; 意图构建成的二叉树如下图所示:
第一种方法:不带参数的二叉树构建
Node *Create()//二叉树的创建,不带参数{ Node *root; if(cin.peek()=='#') {cin.get();return NULL;} else {root = new Node; cin>>root->data;//前序创建。 root->leftchild= Create(); root->rightchild= Create(); return root; }} 可以观察到,返回为节点指针类型。 第二种方法:带一个参数的二叉树创建
void Create(NodePoint* root)//带一个参数的二叉树创建,注意形参为指针的引用或者双重指针{ if(cin.peek()=='#') {cin.get();*root=NULL;} else {*root = new Node; cin>>(*root)->data;//前序创建 Create(&(*root)->leftchild); Create(&(*root)->rightchild); }} 可以观察到,形参为指向节点指针的指针的指针,即双重指针。如上所示,递归和赋值写法稍显不同。 总结方法一,方法二的递归终止条件。使用cin.peek()检查输入流下一个字符是否为“#”,cin.peek()只检查输入流并不抽取删掉。倘若是,结束递归,并使用cin.get()将“#”从输入流抽取并删掉。使用如下代码建立如上图所示的目标二叉树时:
NodePoint Root=NULL;Root=Create();//不带参数构建Create(&Root);//带一个参数构建,此处形参为双重指针输入为:“35 13 0##-15#19##-7##”。当然,两种方法均需要使用前序遍历创建。‘#’控制递归截止,“ ”代表间隔int数据。这两种方法只适合前序创建。
第三种方法:两个形参的二叉树创建函数
void Create( NodePoint &root , int data ){ Node *p = new Node; p->data=data;p->leftchild=0;p->rightchild=0; if(!root) root=p; else if( p->data data ) Create(root->leftchild,p->data ); else Create(root->rightchild,p->data ); } 调用如下: while(data<20){ Create(Root,data);//此处形参为指针的引用,使用此种方法Root必须初始化 data++;} 可以观察到。第一个形参为指针引用,输入参数和赋值参数与第二种方法的形参为双重指针不同。其次,二叉树满足”降顺序二叉数装入数据,满足左<root<=右“.即第三种方法实质是帮助建立一些特殊的二叉树。可以看到,每次输入数据增加节点的时候,均是从根节点开始检索递归。
2.二叉树的递归遍历
void PreTraverse(NodePoint Root)//嵌套前序遍历 { if(Root) {cout< data<<" "; PreTraverse(Root->leftchild); PreTraverse(Root->rightchild);} } void MidTraverse(NodePoint Root)//嵌套中序遍历 { if(Root) {MidTraverse(Root->leftchild); cout< data<<" "; MidTraverse(Root->rightchild);} } void PostTraverse(Node* Root)//嵌套后序遍历 { if (Root ) {PostTraverse(Root->leftchild); PostTraverse(Root->rightchild); cout << Root->data<<" ";}} 3.二叉树销毁
templatevoid destroy(TreeNode *& p) //传递指针的引用,消毁函数,用来消毁二叉树中的各个结点{ if(p) { //错误 return之后 没有执行delete p //return destroy(p->Lchild); //return destroy(p->Rchild); destroy(p->Lchild); destroy(p->Rchild); //delete只能释放由用户通过new方式在堆中申请的内存, //是通过变量声明的方式由系统所声明的栈内存不能使用delete删除 //delete和free函数一样,不修改它参数对应指针指向的内容,也不修改指针本身, //只是在堆内存管理结构中将指针指向的内容标记为可被重新分配 delete p; //堆上内存释放 栈上指针并不销毁 //此时p指向的地址未知,此时执行*p = ? 操作会导致不可预料的错误 //但是可以重新赋值p = &x; //最好delete之后把P置空 p = NULL; }}
容易混淆的错误声明:void destroy(TreeNode* p) 这种声明会创建一个局部的临时对象来保存传递的指针。虽然2个指针都执行同一块堆空间,delete局部指针 也会删除二叉树结构所占用的堆内存,但全局传递的那个指针将会是垃圾指针,会产生不可预料的错误。void destroy(TreeNode *& p) 此函数的参数为全局指针的一个别名,代表全局指针rootNode本身。这样p = NULL;能达到置空指针的目的。
本文有参考自: